Zašto Chat GPT daje smislene, ali netačne odgovore?
ChatGPT nije izveo pogrešne zaključke, već je sve što je naučio razbio u komade i posljedično povezao u odgovor koji nam je predstavio.
Postaviti pitanje računarskoj mašini i od nje dobiti odgovor nije nikakva novost. Nakon Google-ovog asistenta ili Apple-ove Siri, u svijetu chatova potpomognutih vještačkom inteligencijom pojavio se ChatGPT. Ono čime chat-bot impresionira korisnike jesu odgovori u poljima u kojim se vještačka inteligencija tradiconalno smatrala lošom, odnosno ChatGPT je dobar u kreativnom povezivanju koncepata. Kada vam trebaju inspirativne teme i kreativnost koristićete ChatGPT. Međutim, glavna mana je nedostatak tačnosti gotovo u svemu što zahtijeva činjenično znanje. Chatbot zbog načina na koji funkcioniše njegovim korisnicima može dati smislene, ali netačne odgovore. Najbolji primjer nepreciznosti u odgovorima možemo vidjeti na društvenim mrežama – kada neko od naših poznanika objavi potpuno pogrešan odgovor chat-bota na upit o njemu samom.
Zipfov zakon ili koliko je predvidljiv naš govor.
Ljudski jezik, djeluje kao jednostavno sredstvo komunikacije, to je nešto što smo naučili kao djeca, i nešto što koristimo svakodnevno, međutim do pojave ChataGPT, mogli smo vrlo lako primjetiti nedostatak kreativnosti u odgovorima dosadašnjih chat-botova. Ono što jeste iznenađujuće, da ljudi nešto tako kreativno poput jezika ipak koriste na djelomično predvidljiv način.
1944. godine lignvista sa Harvarda, George Kingsley Zipf, objavio je knjigu Načela najmanjeg napora, u kojoj je opisao svoja zapažanja vezana za ljudsko ponašanje. Autor je naveo da “princip najmanjeg napora znači, da će osoba u rješavanju kako neposrednih, tako i predviđenih problema u budućnosti, nastojati da ih riješi tako da uloženi rad svede na najmanju moguću mjeru. Najmanji napor je, dakle, varijanta najmanjeg rada.” Najpoznatiji dio ove knjige odnosi se na statistička zapažanja ljudske komunikacije – odnosno zapažanja o frekvenciji upotrebe određenih riječi u ljudskom govoru, koji proizilazi iz permise autora da i ljudska komunikacija podliježe ovom načelu. Odnosno, ljudi komuniciraju na takav način da se namjanji napor ogleda u kompromisu izgovorenog i odslušanog, odnosno u tome da govornik – pošiljatelj poruke želi misao izreći kao rečenicu najkraćeg mogućeg sadržaja, dok slušatelj želi čuti više kako bi shvatio misao. Zapažanje Zipfa jeste to da se u bilo kojem tekstu, knjizi ili članku, relativno mali broj riječi ponavlja veliki broj puta. Pojavom tehničkih mogućnosti – upotrebom računara za analizu velikih tekstualnih baza podataka poput Wikipedie, napisanih knjiga i publikacija, zapažanja sa polovine prošlog stoljeća su potvrđena i to ne samo za engleski jezik. Riječi se u svim jezicima, pa čak i onim drevnim i neprevedenim, rabe po eksponencijalnom zakonu. Obrazac ponavljanja riječi vrijedi bez obzira da li su najčešće korištene riječi rangirane na cijelom jeziku, samo u jednom tekstu ili u cijeloj knjizi. Druga najčešće korištena riječ pojavit će se otprilike upola češće od najčešće korištene riječi. Učestalost treće najčešće korištene rijeći biti će riječ približna trećini najčešće korištene, učestalost četvrte četvrtinu puta,… i tako redom. Učestalost upotrijebljene riječi je direktno proporcionalan njenom rangu. Ovaj fenomen se zove Zipfov zakon. Matematički rečeno, Zipfov zakon je diskretni oblik eksponencijalne distribucije, odnosno učestalost riječi, predstavljena na eksponencijalnom (log-log) grafiku će biti ravna linija. Pored jezika, učestalost citiranja naučnih radova u odnosu na broj naslova autorâ, broj posjeta na web stranicama u odnosu na broj web stranica, prodaja knjiga u odnosu na broj naslova, broj telefonskih poziva na određeni broj u odnosu na ukupan broj korisnika, broj potresa određene magnitude u odnosu na ukupnu količinu potresa, prečnik i broj kratera na Mjesecu, intenziteti solarnog zračenja, stradanja u ratovima1Kumulativna distribucija intenziteta smrtnih ishoda u 119 ratova od 1816. do 1980. Na primjer, intenziteta Prvog i Drugog svetskog rata je 141,5 odnosno 106,3 poginulih u borbi na 10000. Najgori rat u tom periodu bio je mali, ali užasno destruktivan Paragvajsko-Bolivijski rat 1932-1935. sa intenzitetom od 382,4. … i mnogi drugi fenomeni ili procesi prate Zipfov zakon.
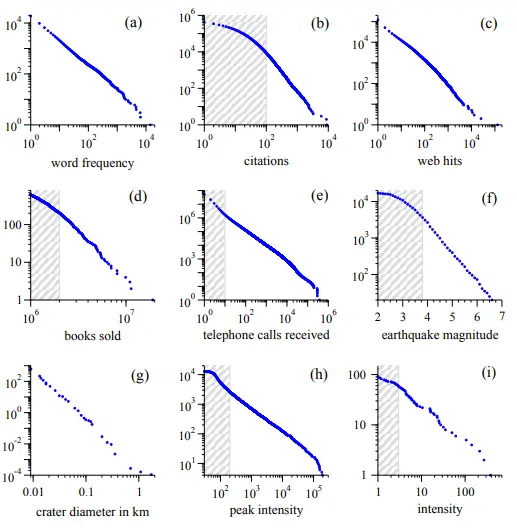
Graf 1 eksponencijalna distribucija2Power laws, Pareto distributions and Zipf’s law M. E. J. Newman ,Department of Physics and Center for the Study of Complex Systems, University of Michigan USA
Paretov princip3Vilfredo Pareto je 1896. pokazao da je otprilike 80% zemlje u Italiji u vlasništvu samo 20% stanovništva. Kasnije je u svojoj bašti ustanovio da 20% mahuna graška sadrži 80% graška. On i drugi istraživači su ustavnovili neravnotežu 80-20 kao veoma čestu u prirodi., s druge strane, važi i za jezike, pa nešto malo manje od 20% korištenih riječi čini preko 80% teksta. Dakle uspostavlja se omjer upotrebe manjeg broja riječi koje se koriste više nego druge, iz ogromnog skupa riječi nekog jezika sa jedne strane i riječi koje se koriste manji broj puta koje daju određeni smisao. Najkorištenija riječ u našem jeziku je “je”, a uporedimo li učestalost4https://wordcounter.net/ riječi klasika književnosti “Ponornice” Skendera Kulenovića i “Tvrđave” Meše Selimovića, najčeše rabljene riječi u obje knjige prate isti omjer “je” (9%), “da” (7%), “se”(6%), “ne”(4%), “što”(2%), “na” (2%), uzmemo li u obzir i broj ponavljanja parova riječi “da je”, učestalost riječi ne odstupa od Zipfovog omjera.
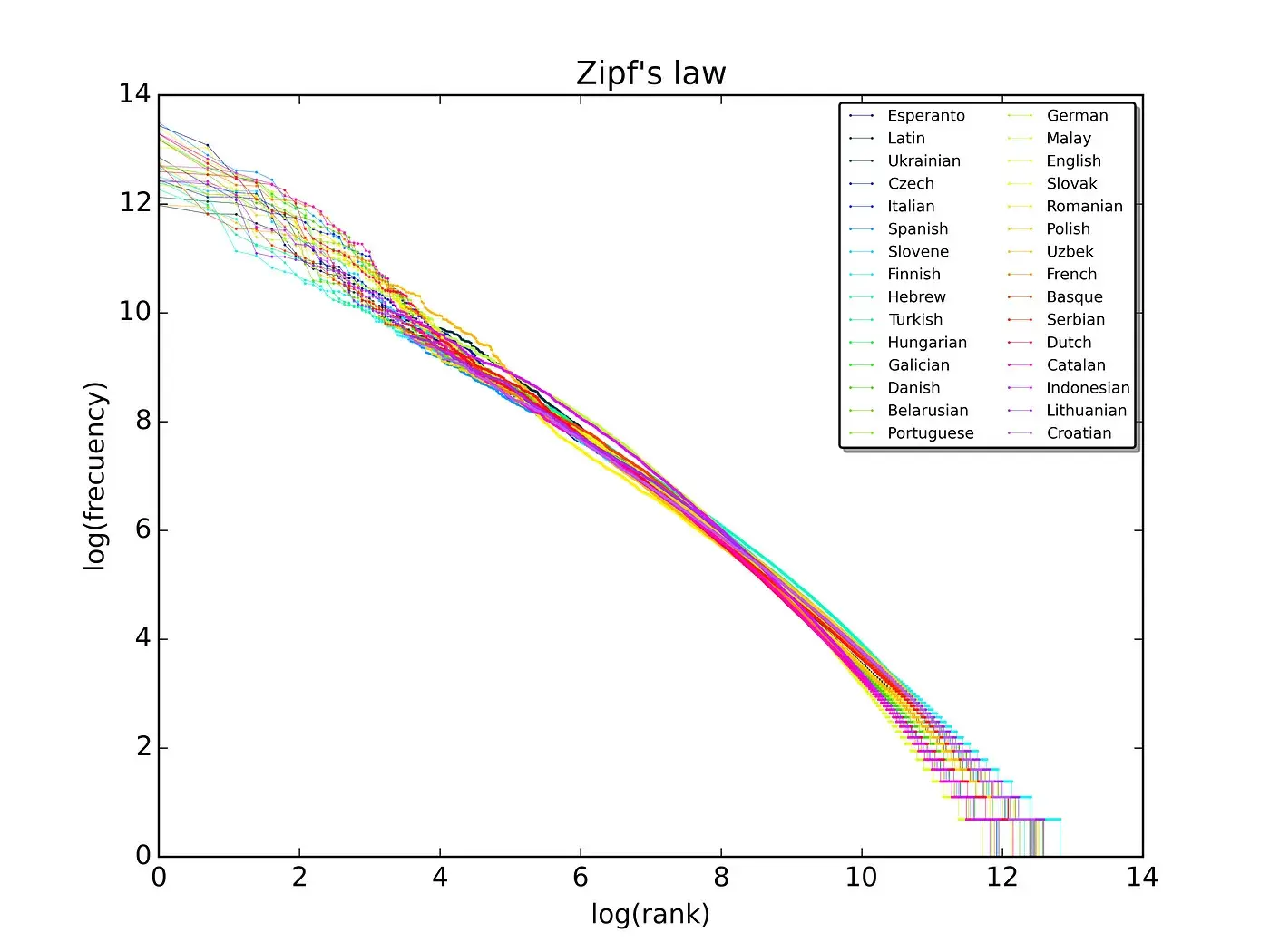
Graf 25https://medium.com/mlearning-ai/zipfs-law-in-whatsapp-ec47c8c38a97 – Zipfova distribucija nad 10 miliona riječi u 30 jezika
Kako možemo koristiti Zipfovo pravilo za predikciju teksta?
Znajući informaciju o učestalosti upotrebe riječi u ne-poetskom tekstu, Zipfov zakon možemo koristiti za računarsko generisanje smislenog teksta. Ukoliko bismo na ovaj način posmatrali, ne samo učestalost pojedinačnih riječi, već i učestalost parova riječi, kao što je u našem jeziku poput ranije pomenutog para “da je”, odnosno skupina više riječi, mogli bismo generisati smisleniji tekst. Širom dostupnošću chat-botova koje pokreće vještačka inteligencija, lingvistička statistika i matematički modeli jezika dobijaju na značaju. Trenutno, ChatGPT-3.5 modeliran je sa 825GiB6https://pile.eleuther.ai/ teksta, pri čemu još uvijek “uči”. Zahvaljujući ogromnoj količini teksta, od chata pogonjenog vještačkom inteligencijom možemo očekivati sintaksički smislene, ali ne nužno i tačne odgovore. Semantičke veze riječi koje identifikuje GPT3 zasnivaju se na učestalosti riječi prije i poslije pozicije u rečenici/tekstu.
Zbog čega onda ChatGPT izmišlja odgovore?
Najlakši primjer izmišljenog odgovora je onda kada se zna da su informacije neistinite. Ukoliko u skup podataka nad kojim vještačka inteligencija uči uključimo veliki broj (reda nekoliko desetina hiljada) pisanih primjera riječi „Elon Musk je osnivač Tesla automobila” onda će vještačka inteligencija pogrešno odgovarati na upite po čemu je poznat Elon Musk. Veliki broj rečenica sa pogrešnim odgovorom umjesto sa tačnim ”Martin Eberhart i Marc Tarpenning su osnivači Tesle” povećavaju vjerovatnoću da će od više desetina hiljada netačnih rečenica o Elonu Musku one postati i najvjerovatniji odgovor za vještačku inteliganciju.
Dakle, na upit: „Ko je Elon Musk?“ vještačka inteligencija mora dati odgovor na postavljeno pitanje, pa će dati izjavu za koju zaključuje da je najvjerovatniji prihvatljiv odgovor na pitanje. Vještačka inteligancija provjerava svoj skup podataka i poznaje sve povezane i slične primjere riječi/koncepata koji su prethodno identificirani. Pa će tako “Elon Musk” biti shvaćeno kao ime, uz stotine hiljada drugih primjera u bazi podataka za koju se vežu pojmovi poput, TESLE, PayPala, Twittera, datuma rođenja, mjesta rođenja, roditelja, zanimanja i drugih…
Odnosno – Vještačka inteligancija nikada zapravo i nije odgovarala na pitanje i nikada nije dala nikakve izjave s namjerom da budu istinite. Netačan daljnji niz odgovora je jednostavno najvjerovatniji s obzirom na ranije pogrešnu netačnu izjavu „Elon Musk je osnivač Tesle“. S obzirom na pogrešne semantičke veze napravljene na početku odgovora, najvjerovatniji je slijed i drugih netačnih odgovora. Vještačka inteligencija je dala najvjerovatniji odgovor na upit, s obzirom na kontekstualne podatke koji su joj dostupni – na isti način na koji daje odgovore koje očekujemo i koji su činjenično tačni. Odnosno ChatGPT nije izveo pogrešne zaključke, već je sve što je naučio razbio u komade i posljedično povezao u odgovor koji nam je predstavio. Matematički model iza ovakvog načina odlučivanja zove se Bayesovo razlučivanje7https://www.lesswrong.com/posts/x7kL42bnATuaL4hrD/bayesian-reasoning-explained-like-you-re-five.
Programiranje vještačke isključivo činjeničnim podacima, u potpunosti ne rješava problem – upotreba samo provjerenih činjenica bi pomogla da ChatuGPT bolje rangira tačniji odgovor na postavljeno pitanje poput odgovora: „Nije osnivač Tesle„. Ovaj odgovor će vrijediti samo uz riječi koje su ispravno identificirane u korelaciji sa postavljenim upitom. Ovakav pristup samo povećava vjerovatnoću da će vještačka inteligencija doći do „tačnog/tačnih“ odgovora/odgovorâ, na postavljeni upit, ali nije isključeno da će i dalje uspostaviti pogrešnu „logiku“ za korelacije koja je i omogućila da se ove greške pojave. Vještačka inteligencija koja iznosi samo istinite izjave i dalje neće poznavati stvarni koncept istine8https://arxiv.org/pdf/2206.08896.pdf, odnosno poznavaće samo koncept vjerovatnih i manje vjerovatnih odgovora na pitanje. Korištenje veoma sofisticiranih i kompleksnih alata poput chatova pogonjenih vještačkom inteligencijom sigurno će unijeti mnogo promjena u svakodnevnom životu, međutim, prilikom njihove upotrebe treba biti svjestan da je samouvjeren i pogrešan odgovor gori nego nikakav odgovor.


